
【论文笔记】BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues

【论文笔记】BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues
小嗷犬基本信息
标题: BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues
作者: Samuel Albanie, Gül Varol, Liliane Momeni, Triantafyllos Afouras, Joon Son Chung, Neil Fox, Andrew Zisserman
发表: ECCV 2020
arXiv: https://arxiv.org/abs/2007.12131

摘要
近年来,在细粒度手势和动作分类以及机器翻译方面的进展,预示着自动手语识别成为现实的可能。
实现这一目标的关键障碍是缺乏适当的训练数据,这源于手语标注的高度复杂性和合格标注者的有限供应。
在本研究中,我们提出了一种新的可扩展方法,用于收集连续视频中的手语识别数据。
我们利用广播视频的弱对齐字幕以及关键词检测方法,自动定位1000小时视频中1000个手势词汇的手语实例。
我们的贡献如下:
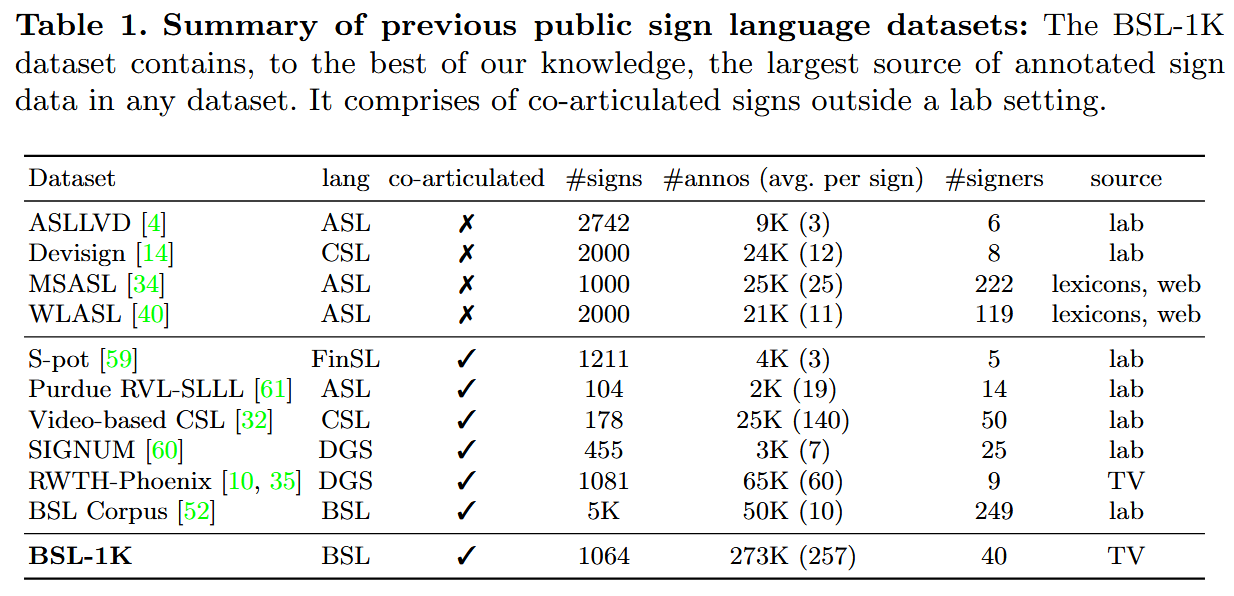
- 我们展示了如何利用手势者的口型提示从视频数据中获得高质量的手语标注——结果是BSL-1K数据集,这是一个前所未有的规模的英国手语(BSL)手势集合;
- 我们展示了如何使用BSL-1K训练强大的BSL共发音手势识别模型,并且这些模型还形成了其他手语和基准的出色预训练——我们在MSASL和WLASL基准上都超越了现有技术;
- 我们提出了新的大规模评估集,用于手语识别和手语定位任务,并提供了基准,希望这些基准能够激发该领域的研究。
Learning Sign Recognition with Automatic Labels
Finding probable signing windows in public broadcast footage
数据集的源材料包括 BBC 制作的 1,412 集公开播出的电视节目,其中包含1,060小时的连续手语翻译。
这些节目涵盖了广泛的题材:医疗剧、历史和自然纪录片、烹饪节目以及涉及园艺、商业和旅行的节目。
手语翻译是对内容的翻译(而非转录),由总共四十名专业手语翻译员制作。
手语表演者占据屏幕的固定区域,并直接从视频中裁剪。
除了视频外,这些节目还配有字幕(总字数约为950万)。
为了在源视频中定位可能出现手语实例的时间窗口,我们首先确定了一个候选词汇表,这些词汇:
- 出现在字幕中;
- 在手语数据库BSL signbank2和手语数据库BSL3中都有条目(以确保查询到的词汇都有有效的手语映射)。
结果是1,350个单词的初始词汇表,这些词汇被用作关键词检测模型的查询,以执行手语定位——这一过程将在下文中进行描述。
Precise sign localisation through visual keyword spotting
通过搜索字幕内容中初始词汇的实例,我们获得了一组可能的时间窗口,其中可能包含手语实例。
然而,两个因素使得这些时间建议极其嘈杂:
- 字幕中存在一个词并不保证它在手语中存在;
- 即使对于有手语字幕的词,我们通过检查发现它们在字幕中的出现可能与手语本身错开几秒钟。
为了应对这一挑战,我们转向视觉关键词检测。
我们的目标是通过对嘴型模式时间序列中的“语音成分”进行识别,精确地检测和定位手语。
这一方法基于两个假设:
- 嘴型在手语产生时提供了强大的定位信号;
- 这种嘴型发生频率足够高,可以形成有用的定位线索。
我们的方法受到手语学文献中研究的启发,这些研究发现语音成分经常被用来识别手语——这通常发生在使用嘴型来区分手语同音异义词时。
然而,即使这些假设成立,任务仍然极具挑战性——手语使用者通常不会持续嘴型,产生的嘴型可能只对应单词的一部分。
因此,现有的唇读方法不能直接应用(实际上,我们使用最先进的唇读模型进行的一次初步探索性实验,在从BBC源素材中随机抽取的五百句手语嘴型句子中,召回率为零)。
视觉关键词检测有效性的关键在于,它不是解决唇读的普遍问题,而是解决在短时间内从一小组候选词中识别单个标记的相对简单问题。
在本工作中,我们使用字幕来构建这样的窗口。
因此,自动手语标注的流程分为两个阶段(图1左侧):
- 对于给定的目标手势,例如“快乐”,确定该手势在视频素材字幕中出现的所有时间点。字幕时间提供了一个短暂的窗口,其中单词被说出,但不一定是其对应的手势产生的时间。因此,我们将候选窗口扩展几秒钟,以提高手势出现在序列中的可能性。
- 然后将得到的时序窗口与目标单词一起提供给关键词检测模型,该模型估计在每个时间步手势被嘴形表达的概率(我们使用步长为0.04秒的关键词检测器——这一选择是基于源素材的帧率为25fps的事实)。当关键词检测器以高置信度断言它已定位到手势时,我们以峰值后验概率的位置作为0.6秒窗口一个端点的锚点(这个值通过视觉检查确定为足够捕捉单个手势)。
BSL-1K dataset construction and validation

实验

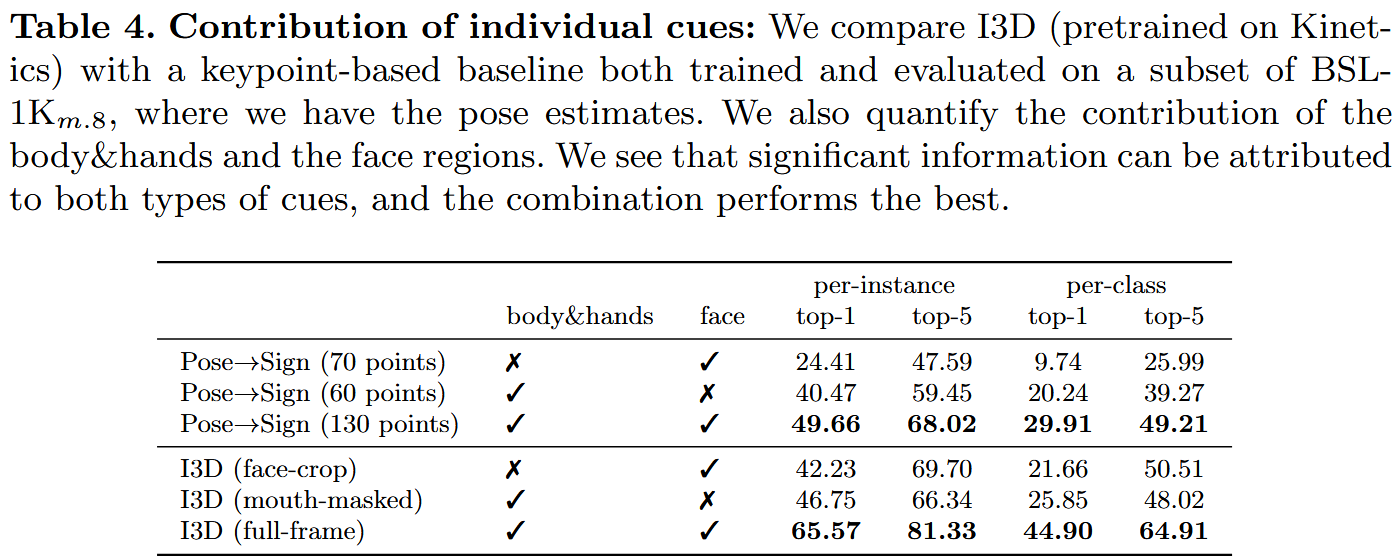
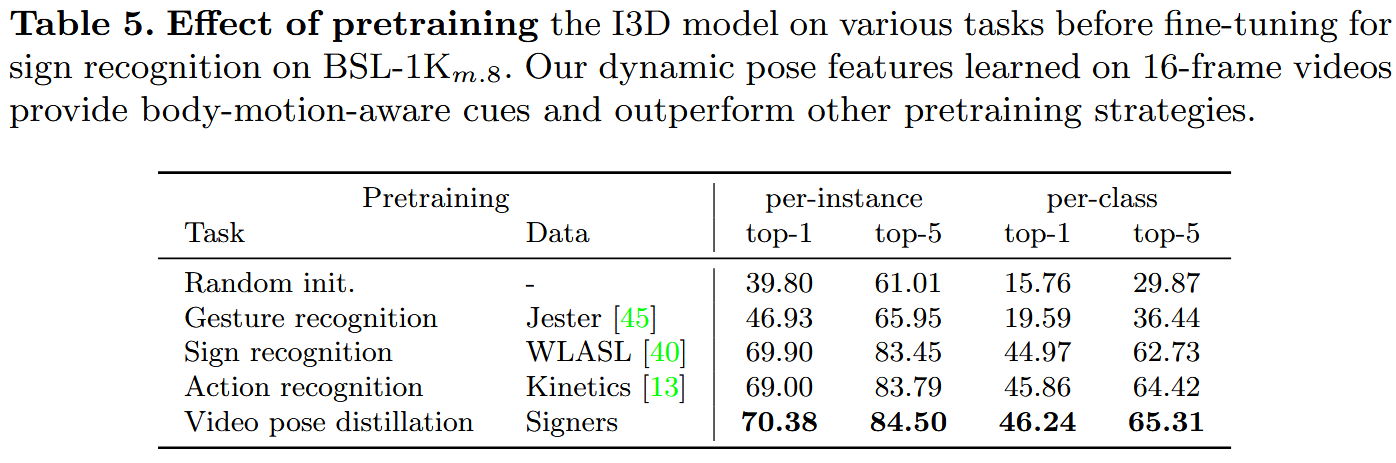

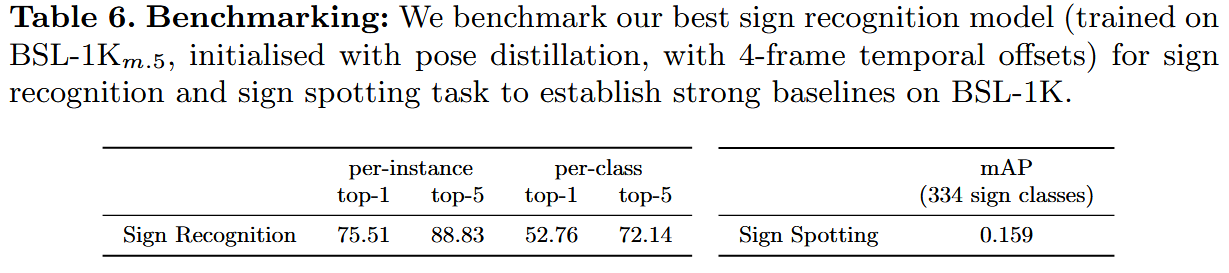
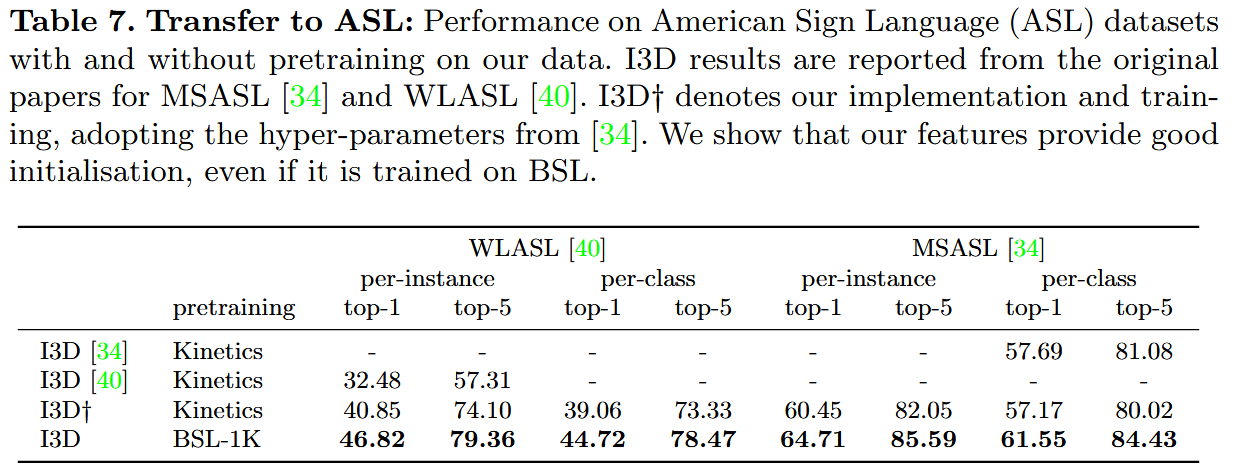
总结
我们已经证明了使用视觉关键词检测来自动标注连续手语视频并添加弱对齐字幕的优势。
我们提出了BSL-1K,这是一个大规模的共发音手势数据集,结合3D卷积神经网络训练,能够实现从大型词汇库中高精度识别手势。
我们的模型还显示出作为ASL基准测试初始化的有益性。
最后,我们为手势识别和手势检测任务提供了消融研究和基线。
一个潜在的未来方向是利用我们的自动标注和识别模型进行手语翻译。































