
【论文笔记】Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining

【论文笔记】Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining
小嗷犬基本信息
标题: Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining
作者: Benjia Zhou, Zhigang Chen, Albert Clapés, Jun Wan, Yanyan Liang, Sergio Escalera, Zhen Lei, Du Zhang
发表: ICCV 2023
arXiv: https://arxiv.org/abs/2307.14768

摘要
手语翻译(SLT)由于其跨领域特性而是一项具有挑战性的任务,涉及将视觉手势语言翻译成文本。
许多先前的方法采用中间表示,即gloss序列,以促进SLT,从而将其转化为两个阶段任务:手语识别(SLR)随后是手语翻译(SLT)。
然而,gloss注释手语数据的稀缺性,加上中级gloss表示中的信息瓶颈,阻碍了SLT任务的进一步发展。
为了应对这一挑战,我们提出了一种基于视觉语言预训练的gloss-free SLT(GFSLT-VLP),通过继承预训练模型中的语言导向先验知识,无需任何gloss注释辅助来提高SLT。
我们的方法包括两个阶段:
- 将对比语言-图像预训练(CLIP)与掩码自监督学习相结合,创建预任务以弥合视觉和文本表示之间的语义差距并恢复掩码句子;
- 构建一个具有编码器-解码器结构端到端架构,从第一阶段继承预训练的视觉编码器和文本解码器的参数。
这些新颖设计的无缝结合形成了一种鲁棒的手语表示,并显著提高了gloss-free手语翻译。特别是,我们在PHOENIX14T数据集(≥+5)和CSL-Daily数据集(≥+3)上实现了前所未有的BLEU-4分数提升,与最先进的gloss-free SLT方法相比。
此外,我们的方法在与大多数gloss-based的方法相比时,在PHOENIX14T数据集上也取得了具有竞争力的结果。
主要贡献
- 在这项工作中,我们未使用gloss注释,在SLT的BLEU-4评分上取得了前所未有的提升。具体来说,与最先进的gloss-free SLT方法相比,我们的方法在PHOENIX14T数据集和CSL-Daily数据集上分别实现了≥+5和≥+3的改进。我们相信,这些改进代表了gloss-free SLT任务中的一个重大突破。
- 据我们所知,这是首次尝试将VLP策略引入到gloss-free的机器翻译任务中,以在联合语义空间中对齐视觉和文本表示。
- 我们提出了一种新的预训练范式,该范式结合了掩码自监督学习和对比语言-图像预训练,以促进gloss-free SLT任务的实现。这种方法相较于先前的方法具有显著改进,并有望大幅提升SLT系统的准确性和效率。
方法
模型架构
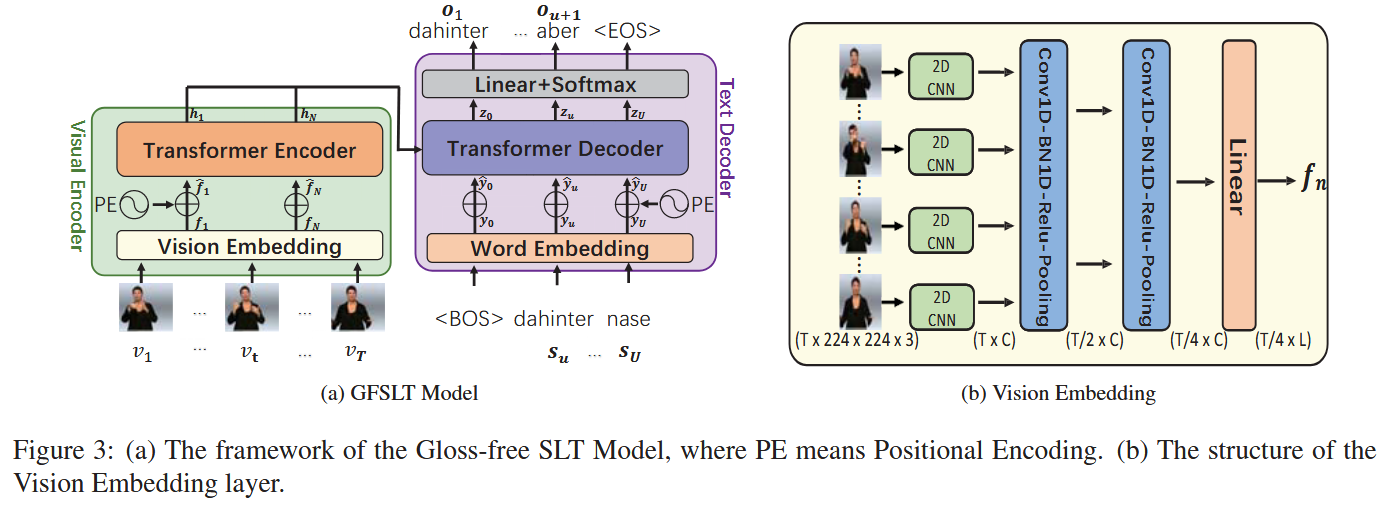
训练

实验
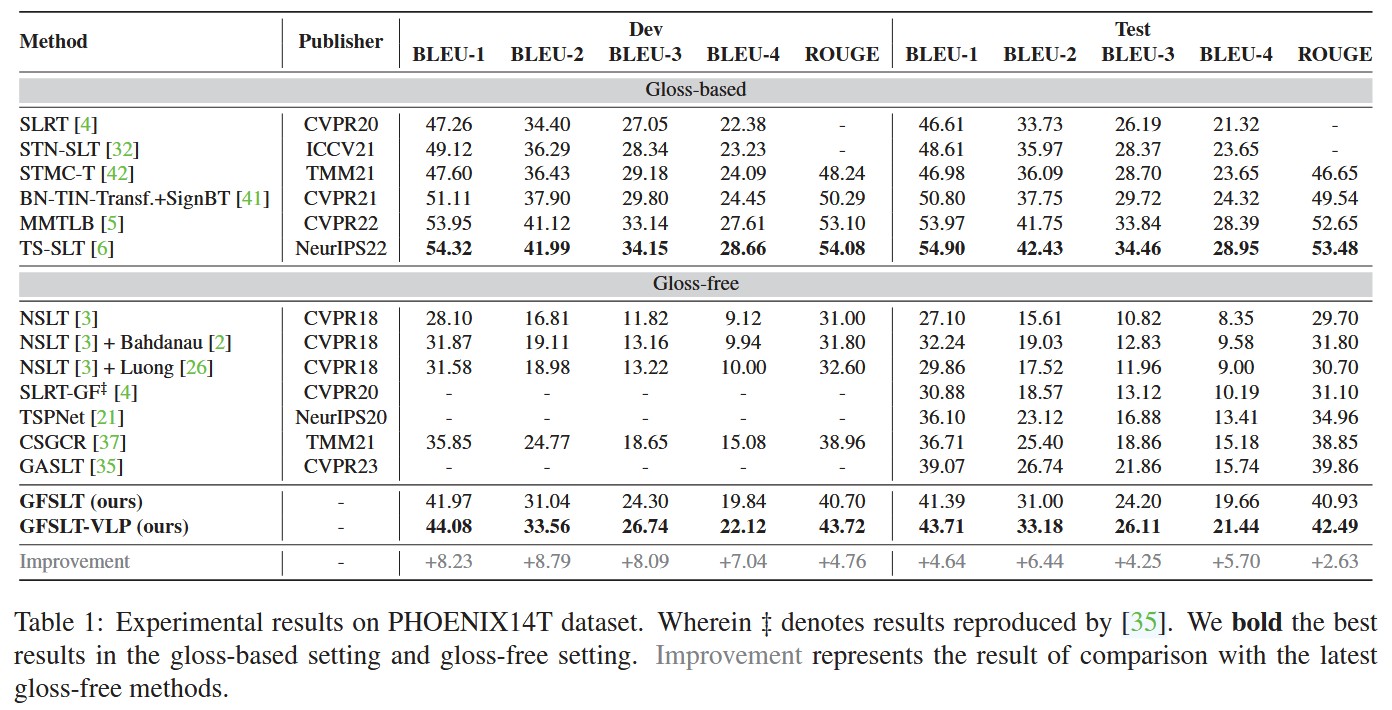
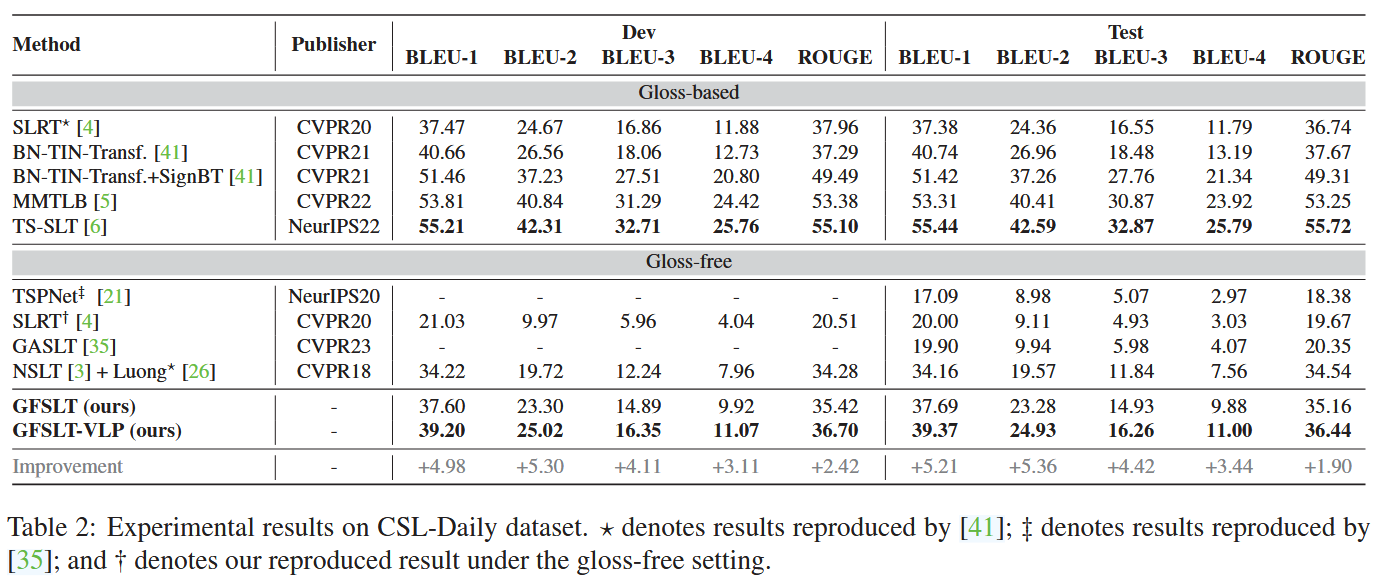
主实验
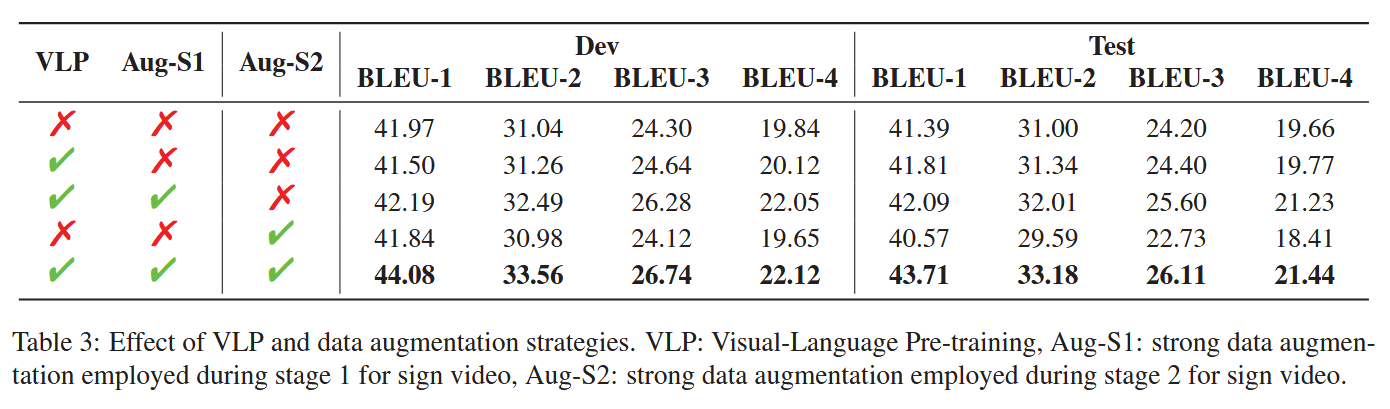
消融实验
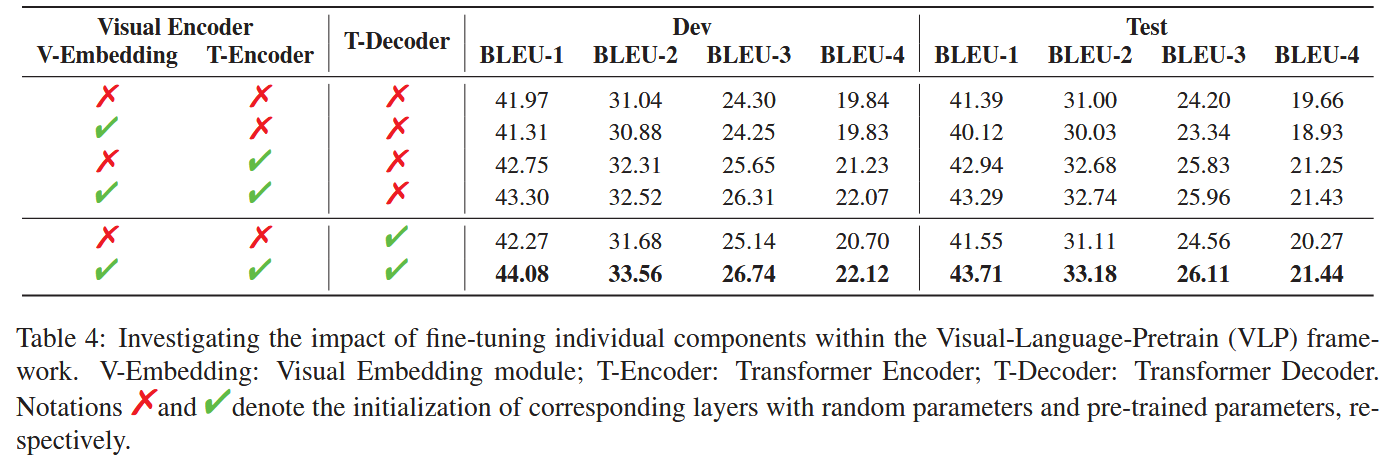

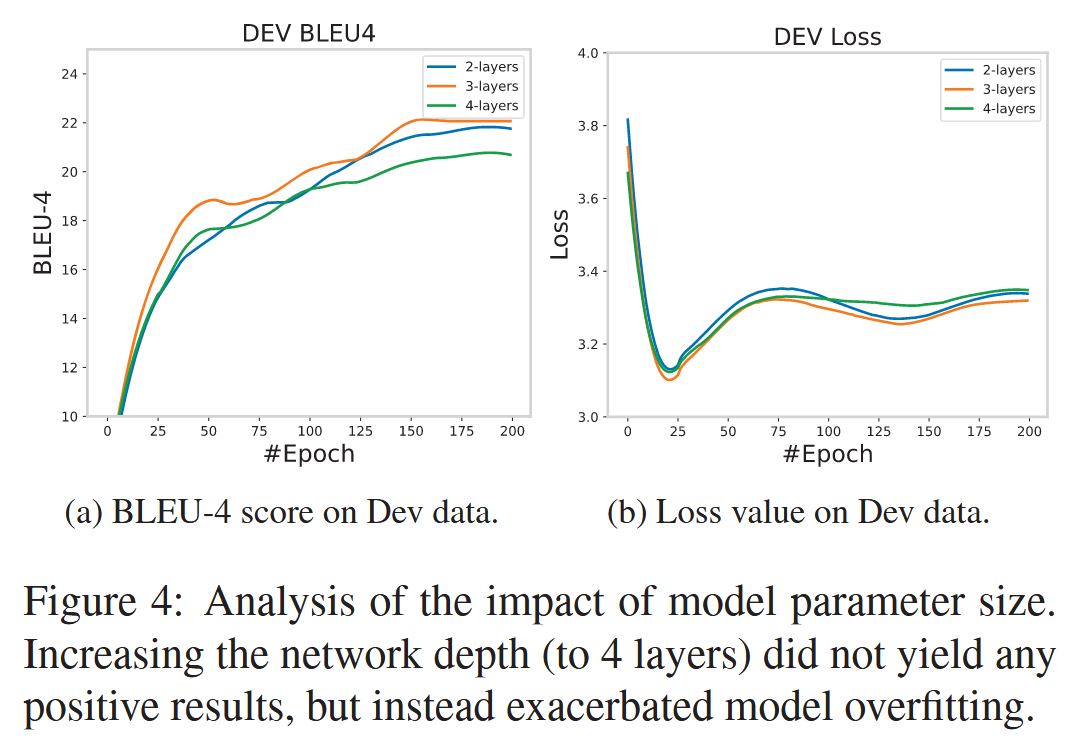

总结
在这项工作中,我们通过缩小视觉和文本表示之间的语义差距,为gloss-free SLT任务提出了一种新的视角,从而使我们能够从手语视频中学习语言指示的视觉表示。
为此,我们引入了一种新的预训练范式,该范式结合了掩码自监督学习和视觉语言监督学习。
我们的实验表明,数据规模和模型参数对该方法性能有显著影响。
虽然我们提出的预训练范式是实现gloss-free SLT的关键步骤,但我们承认还需要进一步的研究,尤其是在大规模SLT数据集(无词标注)上的预训练方面。
我们希望我们的工作能够激发该领域未来的研究。
































