

学习笔记
未读介绍 海象运算符,即 := ,在 PEP 572 中被提出,并在 Python3.8 版本中发布。 海象运算符的英文原名叫Assignment Expresions,即赋值表达式。 它由一个冒号:和一个等号=组成,即:=。而它被称作walrus operator(海象运算符),是因为它长得像一只海象。 语法 海象运算符的语法格式如下: 1variable_name := expression 它的作用是将表达式的值赋值给变量,然后返回表达式的值。 而传统的赋值运算符=在赋值之后,返回的是None。 用法 海象运算符返回的是表达式的值,而不是None,因此可以用于一些需要表达式的地方。 if 语句 使用海象运算符: 12if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)") 传统写法: 123n = len(a)if n > 10: print(f"List is too long ({n ...

实用教程
未读PWA PWA(Progressive Web App)是一种理念,使用多种技术来增强 web app 的功能,可以让网站的体验变得更好,能够模拟一些原生功能,比如通知推送。在移动端利用标准化框架,让网页应用呈现和原生应用相似的体验。 其中我最喜欢的PWA功能就是可以将网页添加到桌面,就像原生应用一样,可以在桌面上创建快捷方式,通过缓存可以实现弱网使用,可以接收通知推送等等。 但是,PWA的安装需要用户点击浏览器的PWA安装按钮。对于不同的浏览器,这个按钮的位置可能有很大的差别,特别是在移动端,该按钮可能会被收纳到一堆浏览器设置选项中,找起来不是很方便;部分浏览器支持PWA,但却没有主动安装PWA的选项,想要安装网站的PWA必须等待网站弹出安装提示,而在移动端部分浏览器中PWA安装提示仅会在第一次弹出,如果用户错过了安装提示可能就无法安装PWA。 因此,我们希望能够将PWA安装按钮固定到网页中,这样用户就可以在任何时候都可以点击安装按钮来安装PWA。 JS手动触发PWA安装窗口 首先要保证自己的网站支持PWA,可以通过Google Lighthouse来检测自己的网站是否支持PWA。 ...
介绍 环境准备 使用到的库: Pytorch matplotlib d2l d2l 为斯坦福大学李沐教授打包的一个库,其中包含一些深度学习中常用的函数方法。 安装: 12pip install matplotlibpip install d2l Pytorch 环境请自行配置。 数据集介绍 CIFAR-10 是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。每个图片的尺寸为32 × 32,每个类别有 6000 个图像,数据集中一共有 50000 张训练图片和 10000 张测试图片。 下载地址: 官网(较慢):http://www.cs.toronto.edu/~kriz/ ...
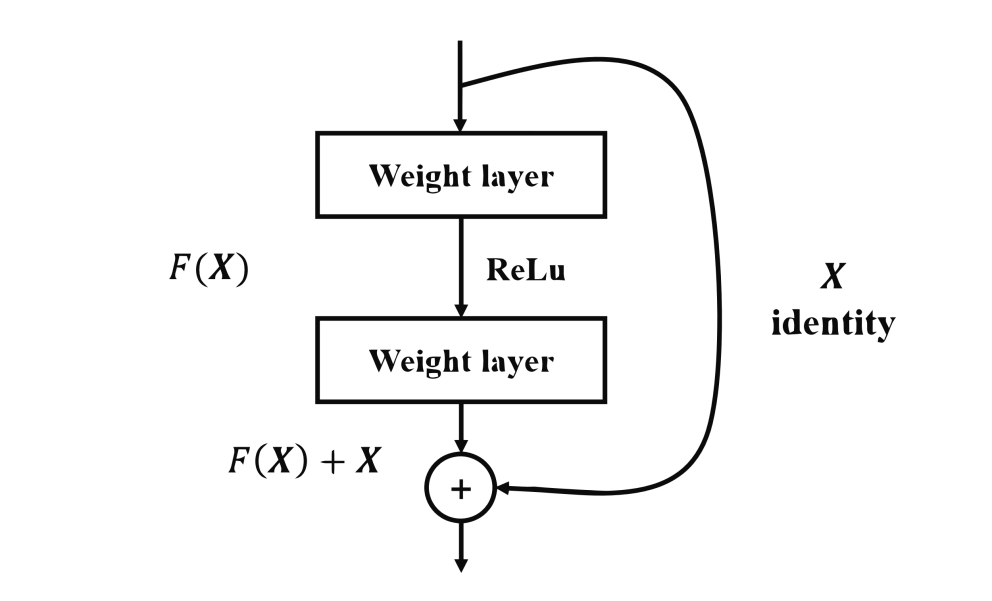
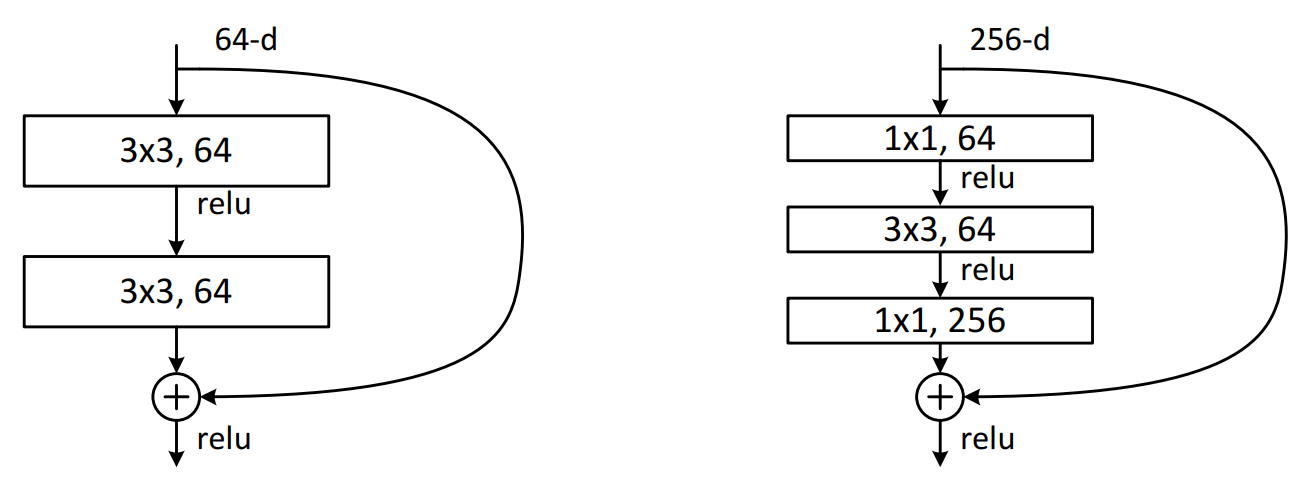
介绍 环境准备 使用到的库: Pytorch matplotlib d2l d2l 为斯坦福大学李沐教授打包的一个库,其中包含一些深度学习中常用的函数方法。 安装: 12pip install matplotlibpip install d2l Pytorch 环境请自行配置。 数据集介绍 Fashion-MNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。 Fashion-MNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。 下载地址: 本文使用 Pytorch 自动下载。 网络模型介绍 残差神经网络(ResNet) 是由微软研究院的 何恺明、张祥雨、任少卿、孙剑 等人提出的。ResNet 在 2015 年的 ILSVRC(ImageNet Large Scale Visual ...
介绍 环境准备 使用到的库: Pytorch matplotlib d2l d2l 为斯坦福大学李沐教授打包的一个库,其中包含一些深度学习中常用的函数方法。 安装: 12pip install matplotlibpip install d2l Pytorch 环境请自行配置。 数据集介绍 Fashion-MNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。 Fashion-MNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。 下载地址: 本文使用 Pytorch 自动下载。 网络模型介绍 Network In Network (NIN) 是由 Min Lin 等人于 2014 年提出,在 CIFAR-10 和 CIFAR-100 分类任务中达到当时的最好水平,其网络结构是由三个 ...
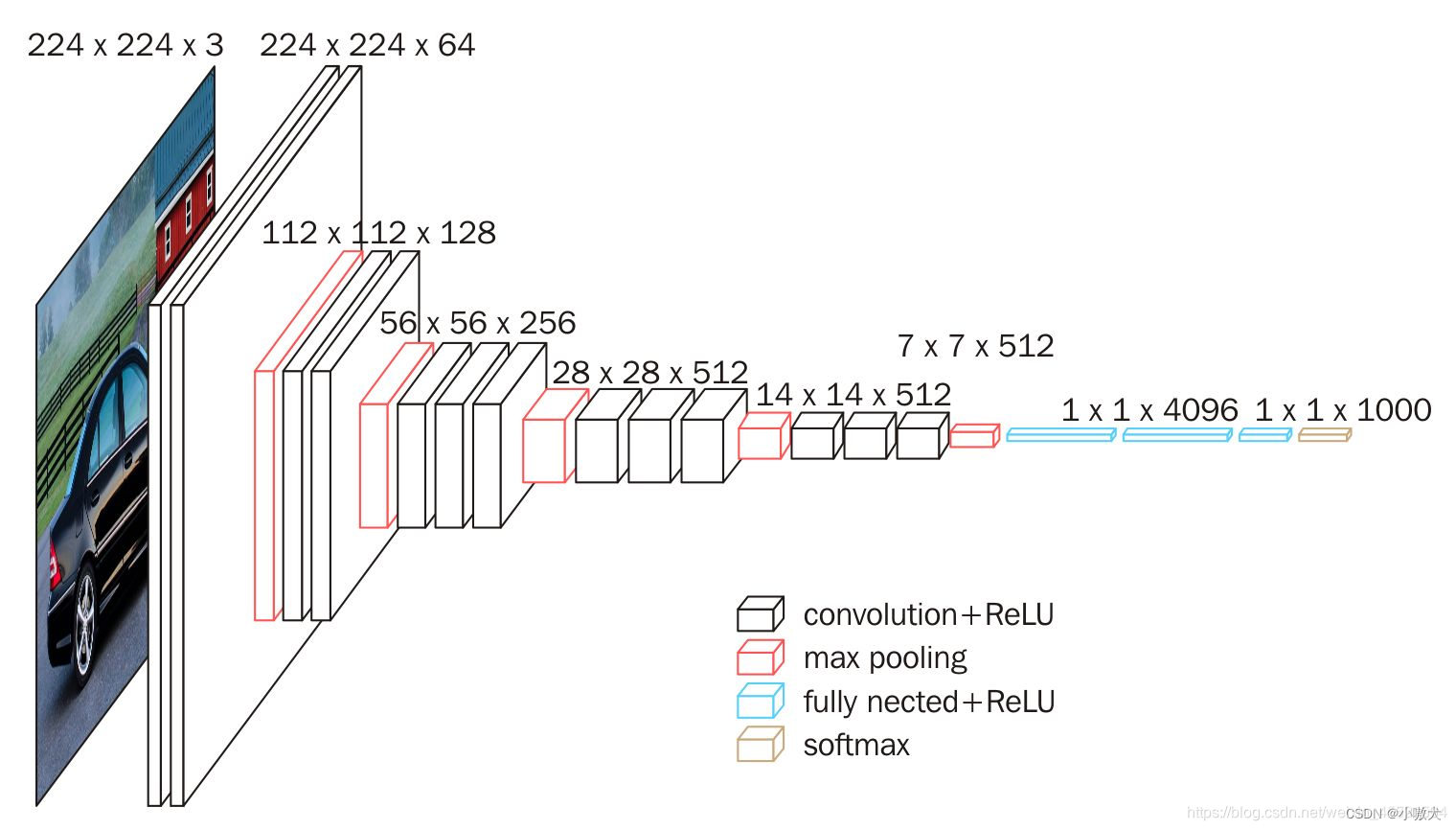
介绍 环境准备 使用到的库: Pytorch matplotlib d2l d2l 为斯坦福大学李沐教授打包的一个库,其中包含一些深度学习中常用的函数方法。 安装: 12pip install matplotlibpip install d2l Pytorch 环境请自行配置。 数据集介绍 Fashion-MNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。 Fashion-MNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。 下载地址: 本文使用 Pytorch 自动下载。 网络模型介绍 VGG-16 网络是 14 年牛津大学计算机视觉组和 Google DeepMind 公司研究员一起研发的深度网络模型。该网络一共有 16 个训练参数的网络,它的兄弟版本如下图所示,清晰的展示 ...
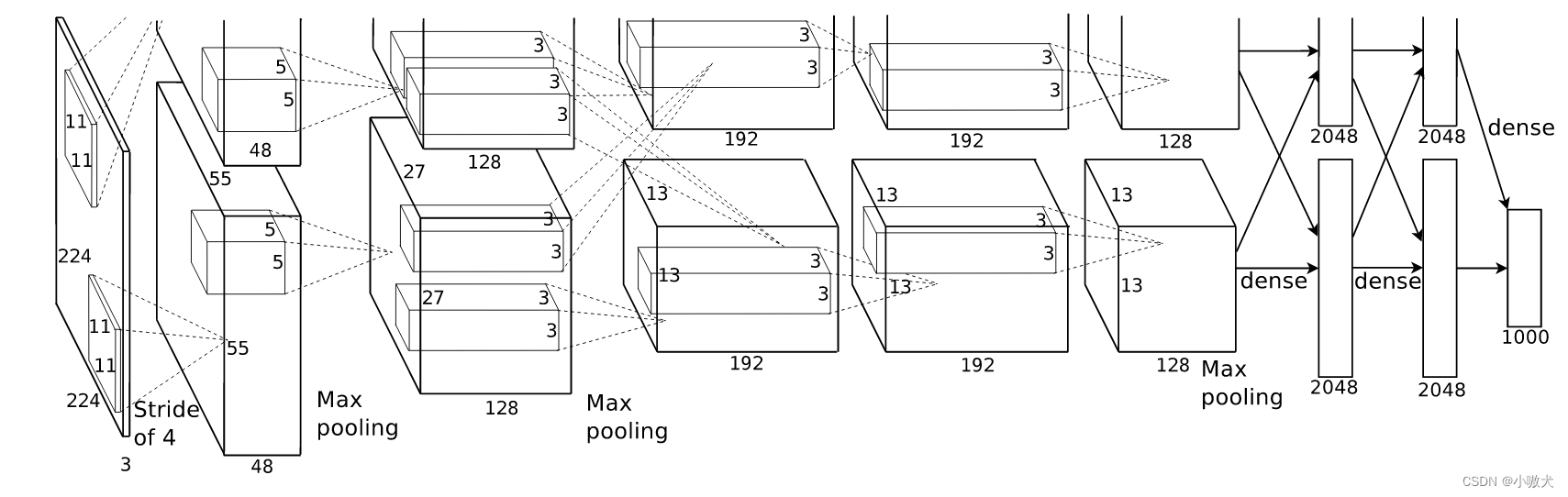
介绍 环境准备 使用到的库: Pytorch matplotlib d2l d2l 为斯坦福大学李沐教授打包的一个库,其中包含一些深度学习中常用的函数方法。 安装: 12pip install matplotlibpip install d2l Pytorch 环境请自行配置。 数据集介绍 Fashion-MNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。 Fashion-MNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。 下载地址 本文使用 Pytorch 自动下载。 网络模型介绍 AlexNet 是 2012 年 ImageNet 竞赛冠军获得者 Hinton 和他的学生 Alex Krizhevsky 设计的。AlexNet 中包含了几个比较新的技术点,也首次在 CNN ...
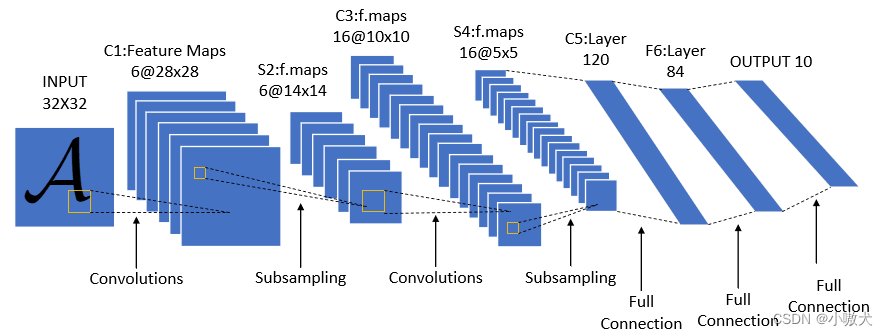
介绍 环境准备 使用到的库: Pytorch matplotlib 安装: 1pip install matplotlib Pytorch 环境配置请自行百度。 数据集介绍 使用 MNIST 数据集(Mixed National Institute of Standards and Technology database)。是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含 60,000 个示例的训练集以及 10,000 个示例的测试集。 下载地址: http://yann.lecun.com/exdb/mnist/ 本文使用 Pytorch 自动下载。 网络模型介绍 LeNet 是由 Yann Lecun 提出的一种经典的卷积神经网络,是现代卷积神经网络的起源之一。本文使用的 LeNet 为 LeNet-5。结构图如下: 导入相关库 12345import torchfrom torch import nnfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoa ...

学习笔记
未读对数组进行索引 我们可以使用行、列索引从数组中提取值,如: 123456789>> x = [1 2 3;4 5 6;7 8 9]x = 1 2 3 4 5 6 7 8 9>> y = x(2,2)y = 5 这样 y 会得到 x 第 2 行第 2 列的值,即数值 5,可以注意到 MATLAB 中的索引是从 1 开始的。 我们可以使用 MATLAB 关键字 end 作为行或列索引来引用最后一个元素: 12345678910111213>> x = [1 2 3;4 5 6;7 8 9]x = 1 2 3 4 5 6 7 8 9>> y = x(2,end)y = 6>> z = x(end,1)z = 7 这里 y 会得到 x 第 2 行最后一列的值,即数值 6;z 会得到 x 最后一行第 1 列的值,即数值 7。 end关键字在这里数值上就等于当前维度的长度, ...
学习笔记
未读输入数组 MATLAB 中的每个数值变量都是一个数组,单个称为标量的数值实际上是一个 1×1 数组,也即它包含 1 行 1 列。 我们可以用方括号[]来创建包含多个元素的数组: 123>> x = [2 3 4]x = 2 3 4 这样我们能够得到一个包含元素2、3、4的数组,也即一个包含元素2、3、4的行向量。 我们可以通过分号;来区分数组中的不同行: 1234>> x = [2 3 4;5 6 7]x = 2 3 4 5 6 7 这样我们能够得到一个2×3数组,第一行包含元素2、3、4,第二行包含元素5、6、7。 创建等间距向量 有的时候,我们会需要一些包含等间距数值的向量,如: 123>> x = [2 3 4]x = 2 3 4 当需要的数值量更多时,我们需要写成这样: 123>> x = [2 3 4 5 6 7 8 9 10 11 12]x = 2 3 4 5 6 7 8 ...

